동일한 종류의 데이터를 저장하는 자료구조 List, Set, Map
List
데이터의 순서를 보장하며 저장하고(순서를 가지며), 중복된 데이터의 저장을 막는 자료구조.
자료구조 List의 기본 구조는 크게 두 종류가 있다.
배열기반 리스트 ArrayList와 노드기반 리스트 LinkedList 가 있음.
| 종류 | 설명 | 구현의 기반이되는 리스트 |
| ArrayList | 배열 기반, 빠른 검색, 끝에 추가 빠름 | 배열(array)기반 |
| LinkedList | 노드 기반, 삽입/삭제 빠름, 검색 느림 | 노드(data+link)기반 |
| CircularList | 원형 연결 리스트, 끝에서 다시 시작 | LinkedList |
| Doubly LinkedList | 양방향 연결 리스트, 삽입/삭제 효율적 | LinkedList |
| Vector | 동기화된 ArrayList, 멀티스레드 환경에서 사용 | ArrayList |
| Stack | LIFO 구조, 마지막에 추가된 데이터 먼저 삭제 | ArrayList, LinkedList |
| Queue | FIFO 구조, 첫 번째로 추가된 데이터 먼저 삭제 | ArrayList, LinkedList |
| Deque | 양방향 큐, 앞뒤에서 삽입/삭제 가능 | ArrayList, LinkedList |
| PriorityQueue | 우선순위 큐, 우선순위가 높은 데이터 먼저 처리 | ArrayList, LinkedList |
배열 기반 리스트 ArrayList
- 동적 배열 기반
- 내부적으로 배열을 사용해 데이터 저장
- 배열의 크기는 필요에 따라 자동 확장
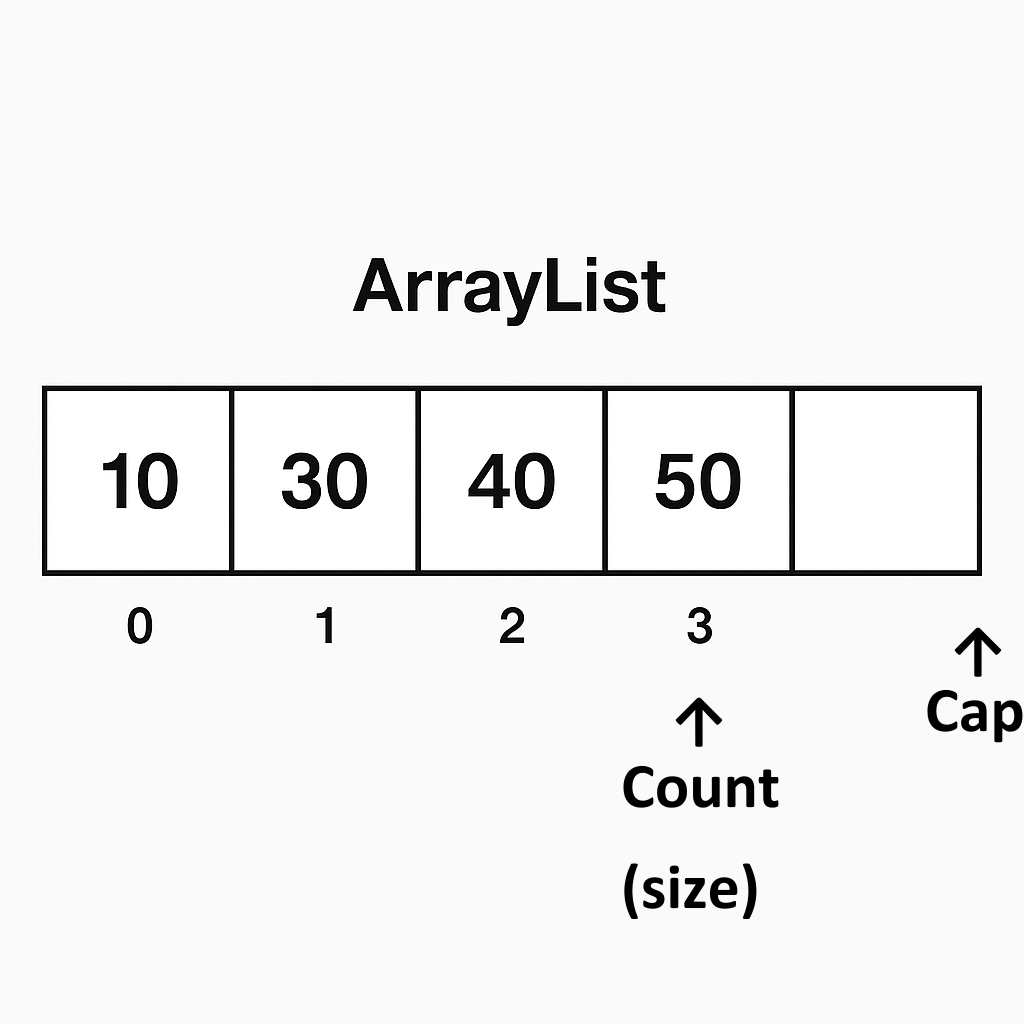
ArrayList 특징
- 빠른 접근: 배열을 사용하기 때문에 인덱스를 통한 데이터 접근은 O(1)의 시간 복잡도를 가짐.
즉, 인덱스를 알고 있다면 매우 빠르게 데이터를 검색할 수 있다. - 빠른 끝에 추가: ArrayList의 끝에 새로운 요소를 추가하는 것은 O(1)의 시간 복잡도를 가짐.
배열의 끝에 데이터를 추가하기 때문에 빠르다.
단, 배열의 크기가 꽉 차면 배열을 재할당하고 복사하는 비용이 발생한다 (이때는 O(n)). - 중간 삽입 및 삭제 느림: 배열에서 중간에 삽입이나 삭제를 하면 O(n)의 시간 복잡도가 걸림.
배열의 요소를 밀어내거나 이동시켜야 하기 때문. - 메모리 효율성: 배열의 크기는 동적으로 늘어날 수 있지만 실제로 사용되는 용량과 배열의 크기 사이에 빈 공간이 생길 수 있어 메모리 낭비가 발생할 수 있다.
→
읽기가 빈번하고, 끝에 추가하는 작업이 주로 필요한 경우에 적합하다.
예를 들어 데이터 조회가 빈번한 경우, 작업 리스트의 추가가 주로 이루어지는 경우.
노드 기반 리스트 LinkedList
- 데이터와 링크로 이루어진 노드 기반
- 각 노드는 데이터와 다음 노드에 대한 참조(링크)를 가짐
- 각 노드들이 포인터로 연결된 구조
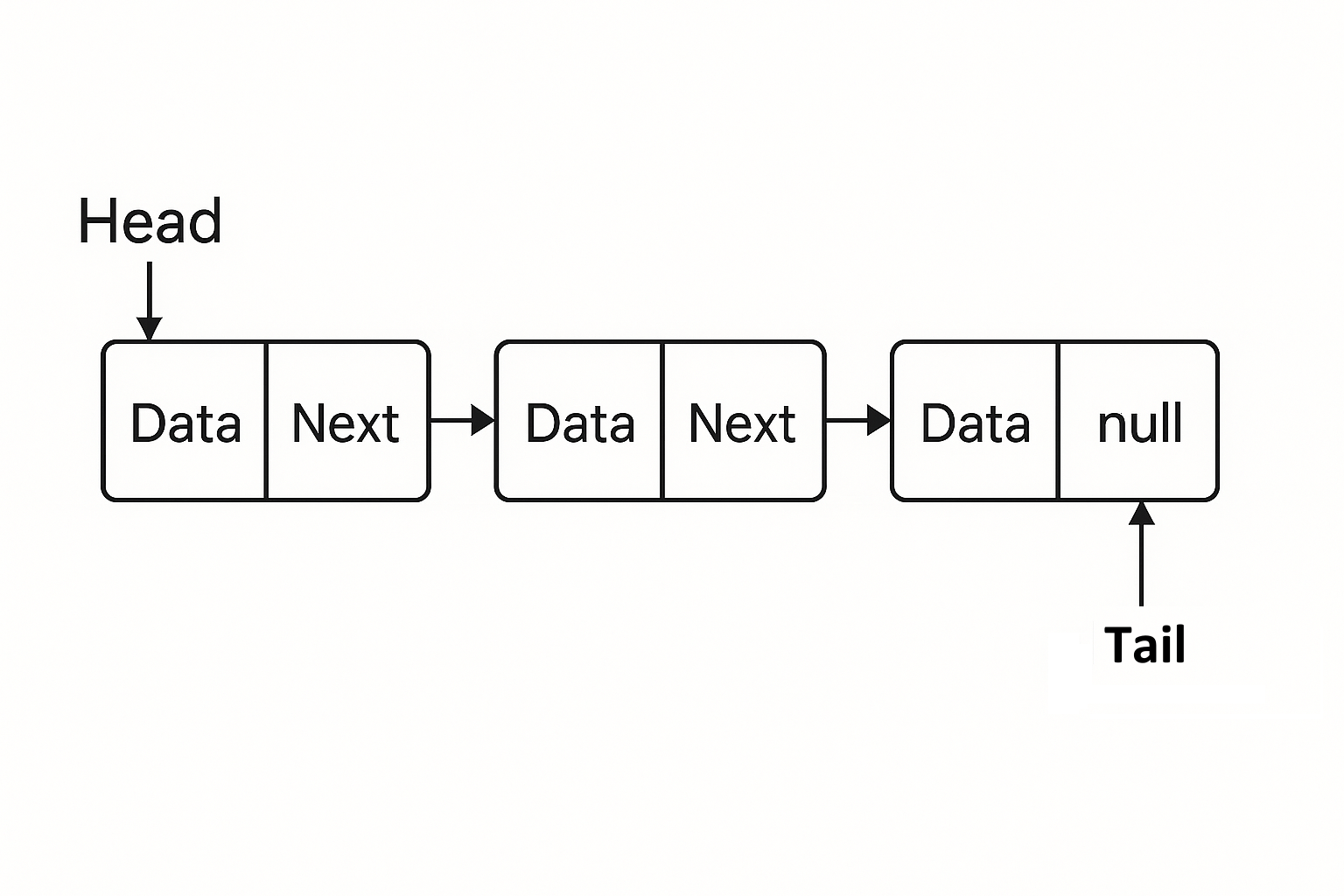
LinkedList 특징
- 빠른 삽입 및 삭제: 리스트의 앞, 뒤, 혹은 중간에서 삽입/삭제가 O(1)로 빠름.
새로운 노드를 삽입하거나 삭제하는 것은 간단히 포인터를 변경하는 작업으로 이루어짐. - 느린 접근: 배열과 달리 인덱스를 통한 접근은 O(n) 시간이 걸림.
각 노드를 차례대로 탐색해야 하기 때문에, 데이터에 접근하는 속도가 느림. - 메모리 사용: 각 노드는 데이터와 함께 포인터(참조)를 저장해야 하므로, 배열에 비해 더 많은 메모리를 사용함.
- 변동 크기: 크기가 동적으로 늘어나기 때문에 크기를 미리 지정할 필요가 없음.
→
삽입과 삭제가 빈번한 경우, 특히 중간 삽입/삭제가 중요한 경우에 적합하다.
예를 들어 빈번한 리스트 수정, 작업 목록 관리, 큐나 스택 구현 등.
Set
집합이라는 의미를 가지며 순서가 없고, 중복을 허용하지 않는 자료구조.
Set의 대표적인 종류는 HashSet, TreeSet, LinkedHashSet 세 종류가 있다.
물론 세 종류만 있는 것은 아니다.
| 종류 | 특징 |
| HashSet | 가장 기본적인 Set. 순서를 보장하지 않음. 빠른 검색과 추가/삭제. |
| LinkedHashSet | 데이터 삽입 순서를 기억하는 HashSet. |
| TreeSet | 데이터를 자동으로 정렬하는 Set. (이진 탐색 트리 기반) |
| EnumSet | 열거형(Enum) 타입 전용 Set. 메모리 효율이 매우 좋음. |
| CopyOnWriteArraySet | 동기화(Synchronized)된 Set. 멀티스레드 환경에 적합. 내부적으로 CopyOnWriteArrayList 사용. |
대표적인 세 가지만 간단하게 알아보자.
해시(Hash) 함수로 데이터를 관리하는 HashSet
- 내부적으로 HashMap을 이용해서 구현됨.
- 데이터가 해시함수를 통해 버킷(bucket)에 저장됨.
(이미지)
HashSet 특징
- 순서 없음 (저장한 순서 유지 안 됨)
- 중복 저장 불가
- 검색, 추가, 삭제가 매우 빠름 (평균 O(1))
- 요소들의 해시코드에 따라 저장 위치가 결정됨
→
중복 없이 데이터 저장이 중요하고, 순서가 상관없는 경우, 빠른 검색과 삭제가 필요한 상황에 적합함.
예를 들어 회원 ID 중복 체크, 방문 기록 중복 제거, 태그 모음 관리, 특정 값 존재 여부 체크 등.
해시함수 기반으로 데이터가 연결된 LinkedHashSet
- HashSet을 상속받으면서 내부에 이중 연결 리스트(Doubly Linked List)를 추가하여 순서를 기억함.
(이미지)
LinkedHashSet 특징
- 삽입 순서 유지
- 검색 속도는 HashSet과 비슷 (조금 느릴 수 있음)
- 중복 저장 불가
- 순서가 중요한 경우 사용 (ex. 입력된 순서대로 출력해야 할 때)
→
데이터 저장 순서 유지가 필요하면서, 중복 제거도 해야 할 경우, 입력한 순서대로 출력해야 하는 상황에 적합함.
예를 들어 최근 본 상품 목록, 최근 검색어 기록, 순서를 유지해야 하는 방문 로그, 순서가 중요한 중복 없는 데이터 저장 등
트리 구조로 데이터를 저장하는 TreeSet
- 내부적으로 Red-Black Tree(레드블랙 트리, 이진 탐색 트리의 일종)를 사용.
(이미지)
TreeSet 특징
- 정렬된 상태로 데이터 저장
(기본 정렬 기준 또는 Comparator 제공 가능) - 검색, 추가, 삭제는 O(log n)
- 중복 저장 불가
- 숫자 크기순, 문자열 사전순 등으로 자동 정렬
→
자동 정렬이 필요하고, 범위 기반 검색(ex. "10보다 큰 값 찾기")도 중요한 경우,
비교적 데이터 양이 적고, 정렬 비용을 감당할 수 있을 때 적합함.
예를 들어 성적순 정렬, 가격순 상품 목록, 알파벳순 이름 정렬, 숫자 범위 내 데이터 조회 등
| Set 종류 | 순서 유지 | 정렬 | 속도(추가/삭제/검색) | 내부 구조 |
| HashSet | ❌ | ❌ | 빠름 (O(1)) | HashMap |
| LinkedHashSet | ⭕ (삽입 순서) | ❌ | 빠름 (조금 느림) | HashMap + LinkedList |
| TreeSet | ❌ (대신 정렬) | ⭕ | 느림 (O(log n)) | Red-Black Tree |
Map
Key-Value 한 쌍의 데이터 값을 가지며 중복을 허용하지 않는 Key값으로 Value값을 쉽게 찾을 수 있는 자료구조.
Map의 종류와 특징은 다음과 같다.
| 종류 | 특징 | 정리 |
| HashMap | 가장 많이 쓰는 기본 Map Hash 기반으로 저장 |
빠른 검색, 순서 보장 X |
| LinkedHashMap | HashMap + 입력 순서 기억 | 순서 유지하면서 빠른 검색 |
| TreeMap | 이진탐색트리(Tree) 기반 Map Key를 정렬 |
Key 정렬 자동 처리 |
| Hashtable | 예전 버전 Map Thread-Safe |
느리지만 동기화 지원 |
| ConcurrentHashMap | 멀티스레드 환경에 최적화 | 빠른 동시 접근 지원 |
Map의 적합한 사용사례를 간단히 보자.
HashMap
→
빠른 검색과 저장이 필요하고, 데이터의 순서나 정렬이 중요하지 않을 때 적합함.
Key를 통해 빠르게 Value를 찾는 것이 최우선인 경우 사용.
예를 들어 회원 ID → 회원 정보 매핑, 상품 코드 → 상품 설명, 키워드 → 검색 결과 리스트 매핑 등
LinkedHashMap
→
입력한 순서를 기억하면서 데이터에 빠르게 접근해야 할 때 적합함.
데이터의 저장 순서를 유지해야 하는 경우 사용.
예를 들어 최근 본 상품 목록 유지, 요청 순서대로 처리해야 하는 작업 관리, API 응답에서 순서가 중요한 데이터 반환 등
TreeMap
→
Key를 기준으로 자동 정렬이 필요하고, 범위 기반 검색(예: 특정 범위 내 Key 조회)이 필요한 경우에 적합함.
Key 값으로 정렬된 데이터 접근이 필요한 경우 사용.
예를 들어 성적순 정렬 (학생 ID → 점수), 시간순 로그 저장 (시간 → 이벤트), 가격순 상품 검색 (가격 → 상품 리스트) 등
Hashtable
→
멀티스레드 환경에서 별도 동기화 처리 없이 Map을 사용해야 할 때 적합함.
다만 최신 코드에서는 잘 쓰이지 않고, 레거시 코드 호환용으로 사용.
예를 들어 과거 Java 프로그램에서 스레드 안전한 Map 사용, 오래된 라이브러리/시스템 유지보수 등
ConcurrentHashMap
→
멀티스레드 환경에서 고성능으로 Map을 읽고 쓸 때 적합함.
부분 잠금을 통해 동시성(Concurrency)을 개선한 구조이기 때문에, 성능이 매우 중요할 때 사용.
예를 들어 대규모 웹서버에서 세션 관리 (세션 ID → 세션 정보), 실시간 게임 서버에서 플레이어 정보 관리, 동시 요청이 많은 캐시 데이터 저장 등
Hash 추가정리
위에서 자주 언급된 Hash 키워드는 무엇인가
Hash란?
어떤 데이터를 고정된 크기의 고유한 값으로 변환하는 기술.
이 변환된 고유 값을 해시값(Hash Value) 또는 해시코드(Hash Code)라고 부름.
한 줄로 Hash = 데이터를 고유 숫자로 바꿔서 빠르게 찾기 위한 기술임.
주요 특징으로는
- 입력 데이터(문자열, 숫자 등)를 고정 길이로 "압축"해서 표현
- 같은 입력이면 항상 같은 해시값 생성
- 다르면 최대한 다른 해시값을 만들려고 함 (충돌을 줄이기 위해)
비유하자면,
책을 읽는 대신, 책의 ISBN 번호만 보고 어떤 책인지 빠르게 찾는 것과 비슷함.
전체 내용을 다 보지 않고 "압축된 고유값"만으로 식별하는 것.
Hash를 사용하는 이유 ::
- 빠른 검색이 가능. (ex: HashMap, HashSet)
- 데이터가 많은 경우에도 O(1) 시간 안에 탐색 가능.
- 중복 체크, 빠른 삽입/삭제 같은 작업에 강력함.
그럼 Hash는 어떻게 만들어지는지?
→
1. 입력 데이터(문자열, 숫자 등)를 받아온다.
2. 특정 규칙(Hash 함수)을 적용해서 입력 데이터를 고정 길이의 숫자(해시코드)로 변환한다.
이 과정에서
각 문자의 아스키코드값을 이용하거나, 여러 숫자를 합치고 곱하고 나누는 방식으로 계산한다.
3. 만들어진 해시값을 이용해
배열 인덱스를 정하거나, 고유한 키로 사용한다.
'정리' 카테고리의 다른 글
| 동기(Synchronous)와 비동기(Asynchronous), blocking과 nonBlocking (0) | 2025.04.27 |
|---|---|
| RDBMS vs NoSQL (0) | 2025.04.26 |
| 스프링 (0) | 2025.04.22 |
| 프로세스와 스레드 (0) | 2025.04.22 |
| MA와 MSA 아키텍처 (0) | 2025.04.19 |


